Unix I/O
所有I/O设备都被模型化为文件, 因此所有输入输出都被当作文件读写, 也因此所有输入输出都可以用一致的方式(Unix I/O)来执行:
- 打开文件
通过内核来打开一个文件,并返回相应的文件描述符.内核记录文件的所有信息打开文件的应用程序只需要记住描述符.
每个进程一开始就有三个描述符:0(标准输入),1(标准输出),2(标准错误),因此其他描述符从3开始. - 改变当前文件的字节偏移量
将文件偏移量改为应有的偏移量. - 读写文件
读文件:从文件复制字节到内存,大于文件大小时返回EOF.
写文件:从内存复制字节到文件,然后更新字节偏移量. - 关闭文件
内核关闭文件,释放打开文件时用的数据结构,使描述符重新可用.
当进程中止时,内核都会关闭其打开的所有文件.
文件
- 普通文件
包括文本文件(内含ASCII 或 Unicode)与二进制文件. - 目录
目录是包含一组链接的文件,每个链接都将一个文件名映射到一个文件(可为另一个目录) - 套接字
用来与另一个进程进行跨网络通信的文件
打开和关闭文件
打开文件
flags参数:
可以使用|符号来一起使用多个参数.
| 参数 | 意义 |
|---|---|
| O_RDONLY | 只读 |
| O_WRONLY | 只写 |
| O_RDWR | 读写 |
| O_CREAT | 若不存在创建一个截断的空文件 |
| O_TRUNC | 若文件已存在就截断 |
| O_APPEND | 每次写之前将文件位置到文件结尾 |
文件截断 : 有时候我们需要在文件尾端处截取一些数据以缩短文件。
mode参数:若为创建一个新文件(O_CREAT), 则可以指定访问权限.
关闭文件使用描述符即可关闭.
读写文件
|
|
Robust I/O:健壮的IO包
无缓冲的输入输出
直接在文件与内存之间传输数据
在将二进制数据读写至网络和从网络读写二进制数据时很有用
有缓冲的输入输出
在rio_t 结构体中的 rio_buf中存作为缓冲,之后再从中读取出来.
rio_t 结构体
rio_readinitb函数 : 绑定fd与rio_t 结构体.
rio_read函数
先从文件读到rio_t结构体缓存区,再memcpy到用户内存.
因为这个函数定义的输入输出与Linux系统中的read函数一致,所以用它来替换上文无缓冲输入输出中的read函数即可得到他的有缓冲版本->rio_readnb.
rio_readlineb函数 : 读取一行
因为rio_readline跟rio_read共用的一个rp结构体
因此只要在第一次if(rc = rio_read(rp,&c,1) == 1)的时候
在rp结构体中的rp->rio_cnt就已经不是0了,因此上一个函数就不需要做while(rp->rio_cnt<=0)
中所做的事情了,而是直接memcpy()来从rp->rio_bufptr中移动一个字符到usrbuf
因此避免了每个字节都陷入内核
读取文件元数据
元数据指用来表示数据的数据
|
|
inode表示文件位置, 更多关于inode可以看inode-Wikipedia
st_mode可以用以下宏谓词来确定文件类型:
读取目录内容
opendir 函数
readdir 函数
closedir函数
关闭目录流并释放资源.
大体来说,读取目录内容的流程为:
1,使用opendir来得到一个指向目录流的指针.
2,使用readdir来一个个读取目录中的所有项目直到返回NULL.
3,再用closedir来关闭目录流.
共享文件
内核如何表示打开的文件
内核用三个相关的数据结构来表示打开的文件
- 描述符表(descriptor table)
每个进程都有自己的描述符表,表中每个表项由进程打开的文件描述符来索引的.每个打开的描述符表项指向文件表中的一个表项 - 文件表(file table)
所有进程共用一个文件表,它表示所有打开的文件的集合.它包括的列有文件位置,引用计数,以及一个指向v-node表中对应表项的指针.内核会在一个表项的引用计数为0时删除一个表项. - v-node 表
同为所有进程共用一张表,每个表项包括st_mode, st_size等stat结构中的大多数信息.
不同于inode, inode只是表示文件位置.

注1:tty可以理解为一个交互环境,如终端.
注2:
On Linux, the set of file descriptors open in a process can be
accessed under the path /proc/PID/fd/, where PID is the process
identifier.
父子进程如何共享打开文件列表
调用fork()前只有父进程表指向文件表的指针,调用fork后子进程增加了对于文件表中相应文件的引用次数.而从file table到vnode table的引用是不受影响的.
I/O重定向
在shell中,可用 > 符号来重定向输出到文件.
另一种方式是使用dup2函数
.
如图,dup(4,1)会将标准输出(fd = 1)重定向到(fd = 4),即指向fileB.
之后fileA将会被关闭, file table到v-node table的引用会被删除, v-node table中对应项也会被释放.
标准I/O(<stdio.h>)
包括:
- 打开关闭文件的函数:fopen(), fclose()
- 读写字节的函数:fread(), fwrite()
- 读写字符串:fgets(), fputs()
- 复杂格式化I/O:scanf(), printf()
标准I/O库将一个打开的文件模型化一个流,即一个指向FILE类型的结构的指针.
每个C程序在一开始就有三个打开的流:12345extern FILE *stdin; 文件描述符为0extern FILE *stdout; 文件描述符为1extern FILE *stderr; 文件描述符为2因为Linux中一切皆文件,所以一开始也打开stdin, stdout, stderr三个文件.
FILE类型的流是对文件描述符和流缓冲区(使开销较大的Linux I/O函数调用次数尽可能小)的抽象.
使用I/O函数的建议与限制
本章讨论的所有I/O函数如下: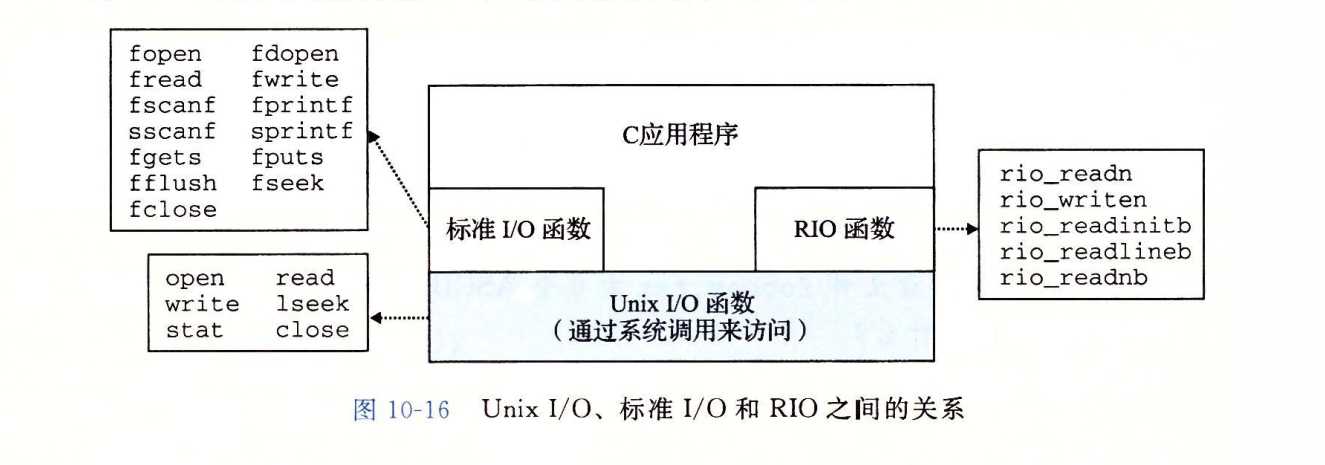
可以看出标准I/O函数与RIO函数都是基于Unix I/O函数来实现的.
使用I/O函数的基本指导与建议:
- 只要有可能就使用标准I/O.
对于磁盘与终端设备I/O来说, 标准I/O是首选. - 不要使用scanf或rio_readlineb来读取二进制文件.
因为二进制文件中可能有0xa字节,而他们在读取文本文件的函数中代表换行,但是在读取二进制文件过程中就会导致错误. - 对网络套接字的I/O使用rio函数
在标准I/O流中又存在着一些限制:
- 限制一:跟在输出函数后的输入函数.如果没有清空缓存区的函数(fflush)或重置当前文件位置的函数(fseek, fsetpos, rewind)调用,不能这样.
限制二:跟在输入函数后的输出函数:若之间没有fseek, fsetpos, rewind的调用,且输入函数又不是自然结束,则不可在其后跟输出函数.
而因为lseek函数在套接字中为非法的,因此不建议在网络套接字的读取中使用标准I/O函数,而是建议使用RIO函数.可用sprintf在内存中格式化一个字符串, 再用rio_writen写.或是用rio_readlineb读取一个文本行,再用sscanf从文本行提取不同字符串.